![]()
|
|
|
|
|---|
[Meßbedingungen] - [Durchführung] - [Laufzeiten] - [Graphiken] - [Detaillierte Resultate] - [Bemerkungen]
![]()
Datum: 06/02/2001
Ausgeführt von: Jasper Möller, moellerj@fmi.uni-konstanz.de
Betriebssystem: Linux 2.2.18
CPU: AMD Athlon, 800MHz
Speicher: 256MB
JDK: 1.3.0, IBM
Javaopt: -Xmx180M
Javacopt: -O
Fahrplandatei: au
Anfragedatei: auswertung-anfragen.au, 50 Anfragen
Für jede Anfrage wurde die Systemzeit (bestimmt mit System.currentTimeMillis()) direkt vor Aufruf von Dikstra.runDijkstra() und direkt danach bestimmt und die Differenz für alle Anfragen addiert:
static long processEvents(...)
{
...
laufzeit = 0;
...
while(cont)
{
...
long begin = 0;
long stop = 0;
...
begin = System.currentTimeMillis();
reisezeit = pathfinder.runDikstra(...);
stop = System.currentTimeMillis();
laufzeit += stop - begin;
...
}
//Alle Anfragen abgearbeitet
return laufzeit;
}
Für jede PriorityQueue wurde dieser Vorgang automatisiert viermal wiederholt und die Ergebnisse gesammelt.
|
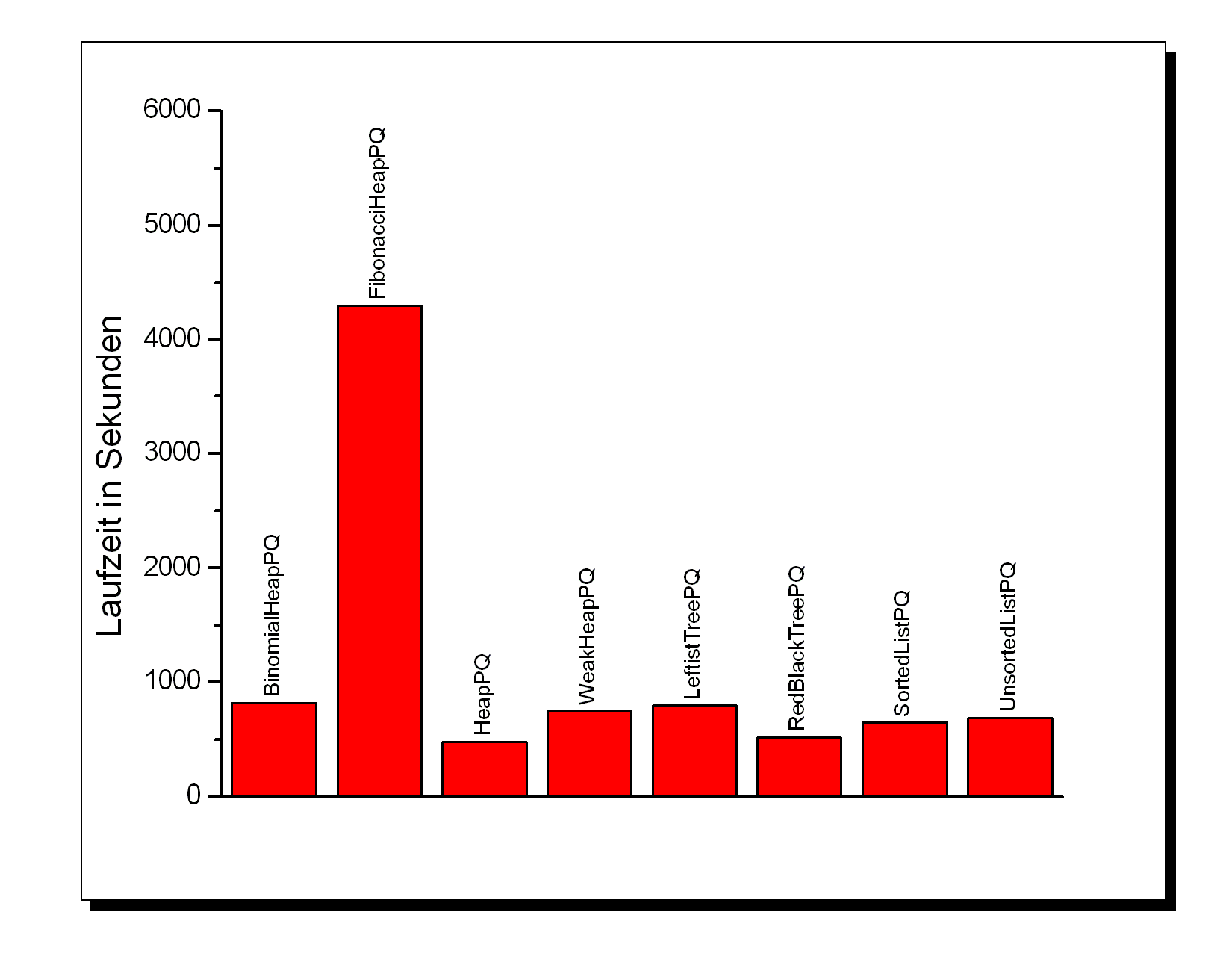
Queue |
BinomialHeapPQ |
FibonacciHeapPQ |
HeapPQ (d=2) |
WeakHeapPQ |
|---|---|---|---|---|
|
Laufzeit (s) |
816,30 |
4298,05 |
478,11 |
750,67 |
|
Queue |
LeftistTreePQ |
RedBlackTreePQ |
SortedListPQ |
UnsortedListPQ |
HeapBucketPQ |
|---|---|---|---|---|---|
|
Laufzeit (s) |
794,73 |
515,97 |
647,25 *) |
687,49 |
496,74 **) |
*) Mittelwert nur aus drei Messungen, da ein Messwert ca. 4x höher als der Rest
**) Da die Ergebnisse der Bucketqueues nur minimal von denen der normalen Queues abweichen, ist hier nur die Bucketqueue mit den besten Einzelkomponenten aufgeführt.
Detaillierte Resultate im Archiv: Fahrplan-Results.tar.gz
Das schlechte Abschneiden der relativ komplexen Queues BinomialHeapPQ, LeftistTreePQ und insbesondere FibonacciHeapPQ dürfte zum einen auf eine verbesserungswürdige Implementation zurückzuführen sein. Insbesondere werden beim FibonacciHeap viele Java-Vectors verwendet, was generell zu keinem guten Zeitverhalten führt. Möglicherweise wäre eine Array-basierte Implementation mit schrittweiser Vergrößerung/Verkleinerung der Datenstruktur lohnender. Zum anderen tritt das gute Zeitverhalten dieser Queues für PriorityQueue.decreaseKey() hier nicht in Erscheinung, da diese Methode für den Fahrplan nicht verwendet wird. Beim WeakHeap ist die Ursache ganz klar in der mangelhaften Optimierung bei der Implementation zu suchen. Allerdings ist diese Datenstruktur in hohem Maße auf In-Place-Sortieralgorithmen zugeschnitten, so daß eine laufzeitoptimale Implementation, die allgemein verwendbar ist, nicht trivial ist.
Die Bucketqueues schneiden insgesamt etwas schlechter ab als die zugehörigen einfachen Queues. Der Unterschied zwischen HeapPQ und HeapBucketPQ gilt so ziemlich genau auch für die anderen Paare.
Bei der HeapPQ ergaben stichpunktartige Änderungen bei der Nachfolgerzahl ein Optimum von fünf Nachfolgern, der Unterschied war aber so gering, daß Meßungenauigkeiten genausogut dafür in Frage kommen können.
Insgesamt traten z.T. relativ große Schwankungen bei der Laufzeit auf, insbesondere bei den einfachen listenbasierten Queues. Dabei ist nicht klar, ob das evtl. am verwendeten JDK oder am Betriebssystem lag. Die sonstige Systemlast blieb im Verlaufe der Messung auf einigermassen gleich niedrigen Level, insbesondere wurden vorher alle nicht nötigen Daemons und die graphische Oberfläche gestoppt und quasi im Single-User-Modus auf der Konsole gemessen. Bei Verwendung der Optimierung beim javac (-O) wurde der Garbage-Collector deutlich seltener verwendet, ein expliziter Aufruf von System.GC() brachte demgegenüber kaum etwas. Insgesamt wurde mit Optimierung (aber ohne JIT) die Streuung der Meßwerte schon deutlich akzeptabler. Cache-Effekte des Betriebssystems beim Einlesen der Daten o.ä. dürften sich dagegen kaum ausgewirkt haben, da während des laufzeitrelevanten Teils keine I/O-Operationen auftreten sollten.
![]()
|
|
|
|
|---|
[Meßbedingungen] - [Durchführung] - [Laufzeiten] - [Graphiken] - [Detaillierte Resultate] - [Bemerkungen]